


LRU缓存淘汰策略
常用缓存淘汰(失效)算法有三种:FIFO,LFU 和 LRU
FIFO(First In First Out):先进先出,也就是淘汰缓存中最老(最早添加)的记录。很多场景下,部分记录虽然是最早添加但也最常被访问,而不得不因为呆的时间太长而被淘汰。这类数据会被频繁地添加进缓存,又被淘汰出去,导致缓存命中率降低。
LFU(Least Frequently Used):最少使用,也就是淘汰缓存中访问频率最低的记录。LFU 算法的命中率是比较高的,但缺点也非常明显,维护每个记录的访问次数,对内存的消耗是很高的;另外,如果数据的访问模式发生变化,LFU 需要较长的时间去适应,也就是说 LFU 算法受历史数据的影响比较大。例如某个数据历史上访问次数奇高,但在某个时间点之后几乎不再被访问,但因为历史访问次数过高,而迟迟不能被淘汰。
LRU(Least Recently Used):最近最少使用,相对于仅考虑时间因素的 FIFO 和仅考虑访问频率的 LFU,LRU 算法可以认为是相对平衡的一种淘汰算法。LRU 认为,如果数据最近被访问过,那么将来被访问的概率也会更高。LRU 算法的实现非常简单,维护一个队列,如果某条记录被访问了,则移动到队尾,那么队首则是最近最少访问的数据,淘汰该条记录即可。
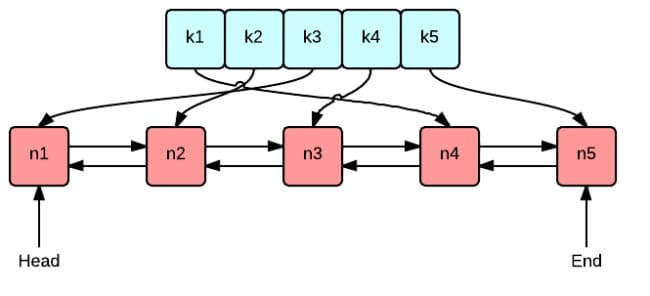
这张图很好地表示了 LRU 算法最核心的 2 个数据结构
- 绿色的是字典(map),存储键和值的映射关系。这样根据某个键(key)查找对应的值(value)的复杂是
O(1),在字典中插入一条记录的复杂度也是O(1)。 - 红色的是双向链表(double linked list)实现的队列。将所有的值放到双向链表中,这样,当访问到某个值时,将其移动到队尾的复杂度是
O(1),在队尾新增一条记录以及删除一条记录的复杂度均为O(1)。
接下来我们创建一个包含字典和双向链表的结构体类型 Cache,方便实现后续的增删查改操作
// Cache 是一个线程安全的LRU缓存。
type Cache struct {
maxBytes int64 // 缓存的最大字节数限制
nbytes int64 // 当前缓存占用的字节数
ll *list.List // 使用双向链表维护最近最少使用的顺序
cache map[string]*list.Element // 将键映射到链表中的元素
mu sync.Mutex // 互斥锁,用于线程安全
OnEvicted func(key string, value Value) // 可选的回调函数,当缓存项被移除时调用
}
type entry struct {
key string
value Value
}
// Vlue使用Len来计算它需要多少字节
type Value interface {
Len() int
} 然后实现查找、删除、新增/修改功能
// Get方法从缓存中获取指定键对应的值
func (c *Cache) Get(key string) (value Value, ok bool) {
c.mu.Lock() // 加锁,保证线程安全
defer c.mu.Unlock() // 确保在函数返回时解锁
// 查找键对应的双向链表节点
if ele, exists := c.cache[key]; exists {
c.ll.MoveToFront(ele) // 将最近访问的节点移动到队首
kv := ele.Value.(*entry)
return kv.value, true // 返回值并标记存在
}
return nil, false
}
// removeOldest是内部方法,用于移除最近最少访问的节点(队尾节点)
func (c *Cache) removeOldest() {
ele := c.ll.Back() // 获取队尾节点
if ele != nil {
c.ll.Remove(ele) // 从链表中移除节点
kv := ele.Value.(*entry)
delete(c.cache, kv.key) // 从缓存字典中删除键
c.nbytes -= int64(len(kv.key)) + int64(kv.value.Len()) // 更新已使用字节数
// 如果有淘汰回调,则调用
if c.OnEvicted != nil {
c.OnEvicted(kv.key, kv.value)
}
}
}
// RemoveOldest是公开方法,用于移除最近最少访问的节点
func (c *Cache) RemoveOldest() {
c.mu.Lock() // 加锁
defer c.mu.Unlock()
c.removeOldest() // 调用内部方法
}
// Add方法将键值对添加到缓存中
func (c *Cache) Add(key string, value Value) {
c.mu.Lock() // 加锁
defer c.mu.Unlock()
// 如果键已存在,则更新值
if ele, exists := c.cache[key]; exists {
c.ll.MoveToFront(ele) // 将节点移动到队首
kv := ele.Value.(*entry)
c.nbytes += int64(value.Len()) - int64(kv.value.Len()) // 更新已使用字节数
kv.value = value // 更新值
} else {
// 键不存在,插入新节点
ele := c.ll.PushFront(&entry{key, value}) // 将新节点插入队首
c.cache[key] = ele // 将节点存入缓存字典
c.nbytes += int64(len(key)) + int64(value.Len()) // 更新已使用字节数
}
// 如果设置了最大字节数并且超过限制,则移除最老的节点
for c.maxBytes != 0 && c.nbytes > c.maxBytes {
c.removeOldest()
}
}单机并发缓存
我们使用 sync.Mutex 封装 LRU 的几个方法,使之支持并发的读写。在这之前,我们要抽象了一个数据结构 ByteView 来表示缓存值,目的是为了更好展示和管理缓存的数据
// ByteView 是一个不可变的字节视图结构。
type ByteView struct {
b []byte // 存储字节数据
}
// Len 返回视图的长度。
func (v ByteView) Len() int {
return len(v.b) // 直接返回底层字节切片的长度
}
// ByteSlice 返回数据的一个副本,作为字节切片。
func (v ByteView) ByteSlice() []byte {
return cloneBytes(v.b) // 调用 cloneBytes 函数复制字节数据
}
// String 将数据作为字符串返回,如果需要,会创建一个副本。
func (v ByteView) String() string {
return string(v.b) // 将字节切片转换为字符串
}
// cloneBytes 复制一个字节切片,返回其副本。
func cloneBytes(b []byte) []byte {
c := make([]byte, len(b)) // 创建一个与原切片等长的新切片
copy(c, b) // 将原切片的内容复制到新切片
return c // 返回副本
} 接下来就可以为 lru.Cache 添加并发特性了
// cache 是一个简单的缓存结构,使用 LRU 算法管理缓存项。
type cache struct {
mu sync.Mutex // 互斥锁,用于保护并发访问
lru *lru.Cache // LRU 缓存实例
cacheBytes int64 // 缓存的最大字节数限制
}
// add 方法向缓存中添加一个键值对。
func (c *cache) add(key string, value ByteView) {
c.mu.Lock() // 加锁,确保并发安全
defer c.mu.Unlock() // 确保在方法结束时释放锁
if c.lru == nil { // 如果 LRU 缓存实例尚未初始化
c.lru = lru.New(c.cacheBytes, nil) // 根据缓存大小限制初始化 LRU 缓存
}
c.lru.Add(key, value) // 将键值对添加到 LRU 缓存中
}
// get 方法从缓存中获取一个键对应的值。
func (c *cache) get(key string) (value ByteView, ok bool) {
c.mu.Lock() // 加锁,确保并发安全
defer c.mu.Unlock() // 确保在方法结束时释放锁
if c.lru == nil { // 如果 LRU 缓存实例尚未初始化
return
}
if v, ok := c.lru.Get(key); ok { // 尝试从 LRU 缓存中获取键对应的值
return v.(ByteView), ok // 如果存在,将值断言为 ByteView 类型并返回
}
return
} 接下来我们实现Group,Group 是 kCache 最核心的数据结构,负责与用户的交互,并且控制缓存值存储和获取的流程
是
接收 key --> 检查是否被缓存 -----> 返回缓存值 ⑴
| 否 是
|-----> 是否应当从远程节点获取 -----> 与远程节点交互 --> 返回缓存值 ⑵
| 否
|-----> 调用`回调函数`,获取值并添加到缓存 --> 返回缓存值 ⑶ 接下来我们将实现流程 ⑴ 和 ⑶,远程交互的部分后续再实现
我们先完成Getter 接口,它定义了如何从某个数据源获取数据的行为。就好像你需要一个东西,但不知道它在哪里,Getter 的作用就是告诉你怎么去找这个东西
// Getter 是一个接口,用于加载键对应的值。
type Getter interface {
Get(key string) ([]byte, error)
}
// GetterFunc 是一个函数类型,实现了 Getter 接口。
type GetterFunc func(key string) ([]byte, error)
// Get 实现了 Getter 接口的方法。
func (f GetterFunc) Get(key string) ([]byte, error) {
return f(key)
} 接下来是最核心数据结构 Group 的定义,它是一个管理缓存的结构体,它结合了缓存功能和数据加载机制
// Group 是一个缓存命名空间,关联了加载数据的逻辑。
type Group struct {
name string
getter Getter
mainCache cache
peers PeerPicker
// 使用 singleflight.Group 来确保每个key只取得一次
loader *singleflight.Group
}
var (
mu sync.RWMutex
groups = make(map[string]*Group)
)
// NewGroup 创建一个新的 Group 实例,并将其注册到全局 map 中。
func NewGroup(name string, cacheBytes int64, getter Getter) *Group {
if getter == nil {
panic("nil Getter")
}
mu.Lock()
defer mu.Unlock()
g := &Group{
name: name,
getter: getter,
mainCache: cache{cacheBytes: cacheBytes},
loader: &singleflight.Group{},
}
groups[name] = g
return g
}
// GetGroup 返回之前通过 NewGroup 创建的 Group 实例,如果不存在则返回 nil。
func GetGroup(name string) *Group {
mu.RLock()
g := groups[name]
mu.RUnlock()
return g
} 可以把它想象成一个图书管理系统的主控中心,假设你有一个图书馆,里面有很多书,为了高效管理这些书,你有一个主控中心(Group),它负责以下事情:
- 图书存储:所有的书都放在主控中心管理的书架上(缓存)。
- 查找图书:当有人需要一本特定的书时,主控中心会先在书架上查找(缓存命中)。如果书架上有这本书,就直接提供给读者。
- 加载图书:如果书架上没有这本书,主控中心会根据规则(
Getter)去其他地方(比如仓库、其他图书馆)找这本书,并把它放到书架上(缓存未命中,加载数据)。 - 优化查找:为了避免重复查找同一本书,主控中心会确保同时来找这本书的多个读者只会让一个人去仓库找书,其他人则等待结果(使用
singleflight.Group确保只加载一次)。
// Get 从缓存中获取键对应的值,如果缓存中不存在,则通过 Getter 加载数据。
func (g *Group) Get(key string) (ByteView, error) {
if key == "" {
return ByteView{}, fmt.Errorf("key is required")
}
if v, ok := g.mainCache.get(key); ok { // 尝试从缓存中获取数据
log.Println("[kCache] hit")
return v, nil
}
return g.load(key) // 缓存中没有命中,加载数据
}
// getLocally 从本地加载数据,并将其填充到缓存中。
func (g *Group) getLocally(key string) (ByteView, error) {
bytes, err := g.getter.Get(key)
if err != nil {
return ByteView{}, err
}
value := ByteView{b: cloneBytes(bytes)} // 创建 ByteView 实例
g.populateCache(key, value) // 将数据填充到缓存
return value, nil
}
// populateCache 将数据添加到缓存中。
func (g *Group) populateCache(key string, value ByteView) {
g.mainCache.add(key, value)
}
// load 方法尝试从本地或远程对等节点加载指定键的值。
// 每个键的加载操作只执行一次,无论有多少并发调用者。
func (g *Group) load(key string) (value ByteView, err error) {
// 使用 singleflight.Group 确保每个键的加载操作只执行一次
viewi, err := g.loader.Do(key, func() (interface{}, error) {
// 如果已注册 PeerPicker,尝试从远程对等节点获取数据
if g.peers != nil {
if peer, ok := g.peers.PickPeer(key); ok {
// getFromPeer从远程对等节点获取数据,会在之后的分布式节点讲到
if value, err = g.getFromPeer(peer, key); err == nil {
return value, nil
}
log.Println("[kCache] Failed to get from peer", err)
}
}
return g.getLocally(key)
})
// 如果加载成功,返回 ByteView 类型的结果
if err == nil {
return viewi.(ByteView), nil
}
return
}HTTP服务器端
分布式缓存需要实现节点间通信,建立基于 HTTP 的通信机制是比较常见和简单的做法,如果一个节点启动了 HTTP 服务,那么这个节点就可以被其他节点访问,因此我们要为单机节点搭建 HTTP Server
// 默认的基础路径和副本数量。
const (
defaultBasePath = "/_kcache/" // 默认的基础路径
defaultReplicas = 50 // 默认的副本数量
)
// HTTPPool 是一个实现 PeerPicker 接口的结构体,用于管理一组 HTTP 对等节点。
type HTTPPool struct {
self string // 当前节点的基础 URL
basePath string // 基础路径
mu sync.Mutex // 互斥锁,保护 peers 和 httpGetters
peers *consistenthash.Map // 一致性哈希映射
httpGetters map[string]*httpGetter // 存储每个对等节点的 httpGetter 实例
} 接下来,实现最为核心的 ServeHTTP 方法
// ServeHTTP 处理所有 HTTP 请求,是 HTTPPool 的核心请求处理函数。
func (p *HTTPPool) ServeHTTP(w http.ResponseWriter, r *http.Request) {
// 检查请求路径是否以 basePath 开头
if !strings.HasPrefix(r.URL.Path, p.basePath) {
panic("HTTPPool serving unexpected path: " + r.URL.Path)
}
p.Log("%s %s", r.Method, r.URL.Path) // 记录请求方法和路径
// 解析请求路径,格式应为 /<basePath>/<groupname>/<key>
parts := strings.SplitN(r.URL.Path[len(p.basePath):], "/", 2)
if len(parts) != 2 {
http.Error(w, "bad request", http.StatusBadRequest) // 如果路径格式不正确,返回400错误
return
}
groupName := parts[0] // 缓存组名
key := parts[1] // 缓存键
group := GetGroup(groupName) // 根据组名获取缓存组
if group == nil {
http.Error(w, "no such group: "+groupName, http.StatusNotFound) // 如果组不存在,返回404错误
return
}
view, err := group.Get(key) // 从缓存组中获取键对应的值
if err != nil {
http.Error(w, err.Error(), http.StatusInternalServerError) // 如果获取失败,返回500错误
return
}
body, err := proto.Marshal(&pb.Response{Value: view.ByteSlice()})
if err != nil {
http.Error(w, err.Error(), http.StatusInternalServerError)
return
}
w.Header().Set("Content-Type", "application/octet-stream") // 设置响应头,表示返回二进制数据
w.Write(body) // 将缓存值写入响应体
}一致性哈希
为什么使用一致性哈希
接下来要实现的是一致性哈希算法,一致性哈希算法是 kCache 从单节点走向分布式节点的一个重要的环节
对于分布式缓存来说,当一个节点接收到请求,如果该节点并没有存储缓存值,那么它面临的难题是,从谁那获取数据?自己,还是节点1, 2, 3, 4…
假设包括自己在内一共有 10 个节点,当一个节点接收到请求时,随机选择一个节点,由该节点从数据源获取数据
假设第一次随机选取了节点 1 ,节点 1 从数据源获取到数据的同时缓存该数据;那第二次,只有 1/10 的可能性再次选择节点 1, 有 9/10 的概率选择了其他节点,如果选择了其他节点,就意味着需要再一次从数据源获取数据,一般来说,这个操作是很耗时的
那有什么办法,对于给定的 key,每一次都选择同一个节点呢?使用 hash 算法也能够做到这一点。那把 key 的每一个字符的 ASCII 码加起来,再除以 10 取余数可以吗?当然可以,这可以认为是自定义的 hash 算法。
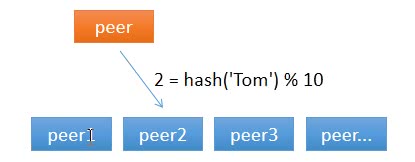
从上面的图可以看到,任意一个节点任意时刻请求查找键 Tom 对应的值,都会分配给节点 2,有效地解决了上述的问题。
但是,节点数量变化了怎么办?
简单求取 Hash 值解决了缓存性能的问题,但是没有考虑节点数量变化的场景。假设,移除了其中一台节点,只剩下 9 个,那么之前 hash(key) % 10 变成了 hash(key) % 9,也就意味着几乎缓存值对应的节点都发生了改变。即几乎所有的缓存值都失效了。节点在接收到对应的请求时,均需要重新去数据源获取数据,容易引起 缓存雪崩。
缓存雪崩:缓存在同一时刻全部失效,造成瞬时DB请求量大、压力骤增,引起雪崩。常因为缓存服务器宕机,或缓存设置了相同的过期时间引起。
那如何解决这个问题呢?一致性哈希算法可以。
算法原理
一致性哈希算法将 key 映射到 2^32 的空间中,将这个数字首尾相连,形成一个环。
- 计算节点/机器(通常使用节点的名称、编号和 IP 地址)的哈希值,放置在环上。
- 计算 key 的哈希值,放置在环上,顺时针寻找到的第一个节点,就是应选取的节点/机器。
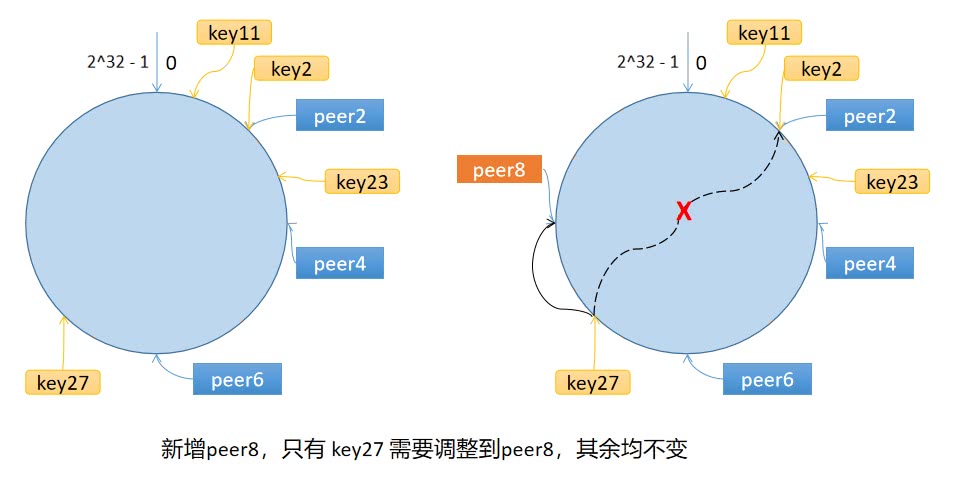
环上有 peer2,peer4,peer6 三个节点,key11,key2,key27 均映射到 peer2,key23 映射到 peer4。此时,如果新增节点/机器 peer8,假设它新增位置如图所示,那么只有 key27 从 peer2 调整到 peer8,其余的映射均没有发生改变。
也就是说,一致性哈希算法,在新增/删除节点时,只需要重新定位该节点附近的一小部分数据,而不需要重新定位所有的节点,这就解决了上述的问题。
如果服务器的节点过少,容易引起 key 的倾斜。例如上面例子中的 peer2,peer4,peer6 分布在环的上半部分,下半部分是空的。那么映射到环下半部分的 key 都会被分配给 peer2,key 过度向 peer2 倾斜,缓存节点间负载不均。
为了解决这个问题,引入了虚拟节点的概念,一个真实节点对应多个虚拟节点。
假设 1 个真实节点对应 3 个虚拟节点,那么 peer1 对应的虚拟节点是 peer1-1、 peer1-2、 peer1-3(通常以添加编号的方式实现),其余节点也以相同的方式操作。
- 第一步,计算虚拟节点的 Hash 值,放置在环上。
- 第二步,计算 key 的 Hash 值,在环上顺时针寻找到应选取的虚拟节点,例如是 peer2-1,那么就对应真实节点 peer2。
虚拟节点扩充了节点的数量,解决了节点较少的情况下数据容易倾斜的问题。而且代价非常小,只需要增加一个字典(map)维护真实节点与虚拟节点的映射关系即可。
// Hash 是一个哈希函数接口,将字节数组映射为 uint32。
type Hash func(data []byte) uint32
// Map 包含所有哈希后的键,并支持一致性哈希。
type Map struct {
hash Hash // 哈希函数
replicas int // 每个键的副本数量
keys []int // 排序后的哈希值列表
hashMap map[int]string // 哈希值到键的映射
}
// New 创建一个新的 Map 实例。
func New(replicas int, fn Hash) *Map {
m := &Map{
replicas: replicas, // 设置副本数量
hash: fn, // 设置哈希函数
hashMap: make(map[int]string), // 初始化哈希映射
}
if m.hash == nil {
m.hash = crc32.ChecksumIEEE // 默认使用 CRC32 哈希函数
}
return m
} 接下来,实现添加真实节点/机器的 Add() 方法,以及实现选择节点的 Get() 方法
// Add 将多个键添加到一致性哈希环中。
func (m *Map) Add(keys ...string) {
for _, key := range keys {
for i := 0; i < m.replicas; i++ {
hash := int(m.hash([]byte(strconv.Itoa(i) + key))) // 为每个副本生成哈希值
m.keys = append(m.keys, hash) // 将哈希值加入列表
m.hashMap[hash] = key // 将哈希值与键关联
}
}
sort.Ints(m.keys) // 对哈希值进行排序
}
// Get 获取与给定键最接近的哈希值对应的键。
func (m *Map) Get(key string) string {
if len(m.keys) == 0 {
return "" // 如果哈希环为空,返回空字符串
}
hash := int(m.hash([]byte(key))) // 计算目标键的哈希值
// 使用二分查找找到合适的副本位置
idx := sort.Search(len(m.keys), func(i int) bool {
return m.keys[i] >= hash
})
// 返回最接近的键
return m.hashMap[m.keys[idx%len(m.keys)]] // 如果超出范围,循环回到列表开头
}分布式节点
是
接收 key --> 检查是否被缓存 -----> 返回缓存值 ⑴
| 否 是
|-----> 是否应当从远程节点获取 -----> 与远程节点交互 --> 返回缓存值 ⑵
| 否
|-----> 调用`回调函数`,获取值并添加到缓存 --> 返回缓存值 ⑶ 我们在中单机并发缓存已经实现了流程 ⑴ 和 ⑶,现在实现流程 ⑵,从远程节点获取缓存值。
我们进一步细化流程 ⑵:
使用一致性哈希选择节点 是 是
|-----> 是否是远程节点 -----> HTTP 客户端访问远程节点 --> 成功?-----> 服务端返回返回值
| 否 ↓ 否
|----------------------------> 回退到本地节点处理。 我们使用protobuf来作为节点的通信协议,proto文件如下
syntax = "proto3";
option go_package = ".;proto";
message Request {
string group = 1;
string key = 2;
}
message Response {
bytes value = 1;
}
service GroupCache {
rpc Get(Request) returns (Response);
} 接着抽象出分布式节点的 PeerPicker 接口
// PeerPicker 是一个接口,用于定位拥有特定键的对等节点(peer)。
// 实现该接口的类型需要提供一个方法来选择对等节点。
type PeerPicker interface {
// PickPeer 方法根据给定的键选择一个对等节点。
// 如果找到合适的对等节点,则返回该节点的 PeerGetter 接口实例和 true;
// 否则返回 nil 和 false。
PickPeer(key string) (peer PeerGetter, ok bool)
}
// PeerGetter 是一个接口,表示对等节点(peer)的功能。
// 实现该接口的类型需要提供一个方法来从对等节点获取数据。
type PeerGetter interface {
// Get 方法从对等节点获取指定分组和键的值。
// 如果成功获取数据,返回字节切片;否则返回错误。
Get(in *pb.Request, out *pb.Response) ([]byte, error)
} 在HTTP服务器端中我们为 HTTPPool 实现了服务端功能,通信不仅需要服务端还需要客户端,因此,我们接下来要为 HTTPPool 实现客户端的功能。
首先创建具体的 HTTP 客户端类 httpGetter,实现 PeerGetter 接口。
// httpGetter 是一个用于从远程 HTTP 服务器获取数据的结构体。
type httpGetter struct {
baseURL string // 基础 URL,用于构建完整的请求地址
}
// Get 方法通过 HTTP GET 请求从远程服务器获取指定键的值。
func (h *httpGetter) Get(in *pb.Request, out *pb.Response) ([]byte, error) {
// 构建完整的请求 URL,包括对 group 和 key 的 URL 编码。
u := fmt.Sprintf(
"%v%v/%v",
h.baseURL,
url.QueryEscape(in.GetGroup()),
url.QueryEscape(in.GetKey()),
)
// 发起 HTTP GET 请求。
res, err := http.Get(u)
defer res.Body.Close() // 确保响应体在函数返回时关闭
// 检查 HTTP 响应状态码。
if res.StatusCode != http.StatusOK {
return nil, fmt.Errorf("server returned: %v", res.Status) // 如果状态码不是 200 OK,返回错误
}
// 读取响应体内容。
bytes, err := ioutil.ReadAll(res.Body)
if err = proto.Unmarshal(bytes, out); err != nil {
return nil, fmt.Errorf("decoding response body: %v", err)
}
if err != nil {
return nil, fmt.Errorf("reading response body: %v", err) // 如果读取失败,返回错误
}
return bytes, nil // 返回读取到的数据
} 之后,实现 PeerPicker 接口,实现对HTTP池中的创建和选择
// Set 方法更新节点池中的对等节点列表。
func (p *HTTPPool) Set(peers ...string) {
p.mu.Lock()
defer p.mu.Unlock()
p.peers = consistenthash.New(defaultReplicas, nil) = // 创建一致性哈希映射
p.peers.Add(peers...) // 添加节点
p.httpGetters = make(map[string]*httpGetter, len(peers)) // 初始化 httpGetters 映射
for _, peer := range peers {
p.httpGetters[peer] = &httpGetter{baseURL: peer + p.basePath} // 为每个节点创建 httpGetter 实例
}
}
// PickPeer 方法根据键选择一个节点。
func (p *HTTPPool) PickPeer(key string) (PeerGetter, bool) {
p.mu.Lock()
defer p.mu.Unlock()
if peer := p.peers.Get(key); peer != "" && peer != p.self { // 根据键选择节点
p.Log("Pick peer %s", peer) // 日志记录
return p.httpGetters[peer], true // 返回节点的 httpGetter 实例
}
return nil, false // 如果没有找到合适的节点,返回 nil
}
// 确保 HTTPPool 实现了 PeerPicker 接口。
var _ PeerPicker = (*HTTPPool)(nil) 最后,我们需要将上述新增的功能集成在主流程(kcache.go)中
// RegisterPeers 注册一个 PeerPicker,用于选择远程对等节点。
// PeerPicker 负责根据键选择合适的对等节点。
func (g *Group) RegisterPeers(peers PeerPicker) {
if g.peers != nil {
panic("RegisterPeerPicker called more than once") // 确保只调用一次
}
g.peers = peers // 将 PeerPicker 实例绑定到缓存组
}
// getFromPeer 从指定的对等节点获取数据。
func (g *Group) getFromPeer(peer PeerGetter, key string) (ByteView, error) {
req := &pb.Request{
Group: g.name,
Key: key,
}
res := &pb.Response{}
_, err := peer.Get(req, res)
if err != nil {
return ByteView{}, err
}
return ByteView{b: res.Value}, nil
}防止缓存击穿
在分布式节点中,提到了缓存雪崩和缓存击穿,在这里做下总结:
缓存雪崩:缓存在同一时刻全部失效,造成瞬时DB请求量大、压力骤增,引起雪崩。缓存雪崩通常因为缓存服务器宕机、缓存的 key 设置了相同的过期时间等引起。
缓存击穿:一个存在的key,在缓存过期的一刻,同时有大量的请求,这些请求都会击穿到 DB ,造成瞬时DB请求量大、压力骤增。
缓存穿透:查询一个不存在的数据,因为不存在则不会写到缓存中,所以每次都会去请求 DB,如果瞬间流量过大,穿透到 DB,导致宕机。
假设程序同时发起了 N 次请求,同时假设对数据库的访问没有做任何限制的,那么很可能向数据库也发起 N 次请求,容易导致缓存击穿和穿透
即使对数据库做了防护,HTTP 请求是非常耗费资源的操作,针对相同的 key,节点发起多次请求也是没有必要的,因此,我们要做到只向远端节点发起一次请求
首先我们在singleflight创建 call 和 Group 类型;call 代表正在进行中,或已经结束的请求。使用 sync.WaitGroup 锁避免重入;Group是 singleflight 的主数据结构,管理不同 key 的请求(call)
// call 用于存储函数调用的结果。
type call struct {
wg sync.WaitGroup // 用于同步等待函数执行完成
val interface{} // 函数返回的值
err error // 函数执行过程中可能发生的错误
}
// Group 是一个并发控制结构体,确保同一个 key 的函数只执行一次。
type Group struct {
mu sync.Mutex // 保护 map 的互斥锁
m map[string]*call // 存储 key 和对应的 call 实例
} 然后我们实现 Do 方法确保同一个 key 的函数 fn 只会被执行一次
// Do 方法确保同一个 key 的函数 fn 只会被执行一次。
func (g *Group) Do(key string, fn func() (interface{}, error)) (interface{}, error) {
g.mu.Lock()
if g.m == nil {
g.m = make(map[string]*call) // 初始化 map
}
if c, ok := g.m[key]; ok {
g.mu.Unlock() // 如果 key 已存在,释放锁
c.wg.Wait() // 等待函数执行完成
return c.val, c.err // 返回已缓存的结果
}
c := new(call) // 创建一个新的 call 实例
c.wg.Add(1) // 增加 WaitGroup 的计数
g.m[key] = c // 将 call 实例存储到 map 中
g.mu.Unlock() // 释放锁
// 执行函数 fn 并存储结果
c.val, c.err = fn()
c.wg.Done() // 函数执行完成,减少 WaitGroup 的计数
g.mu.Lock() // 再次加锁
delete(g.m, key) // 删除 map 中的 key
g.mu.Unlock() // 释放锁
return c.val, c.err // 返回函数的结果
}总结
分布式缓存,提升性能,解决高并发问题,实现资源高效利用和数据共享,如企业之“现金”,架构之关键。
Comments NOTHING